



Prelude
The infinitesimally small quantum mechanics world gifted humanity with photons and electrons, magical particles that drive virtually all electronic communication. Claude Shannon stood on top of the shoulders of two giants, Ralph Hartley and Harry Nyquist, when he set forth the revolutionary work on information theory (communication systems). These three scientists laid down the underlying mathematical models and architectures that govern modern digital information systems. From radio and television to cell services, instant messaging, and video streaming, the scientific trio’s footprint is massive yet subtle.
Nothing was a blessing to the scientific community and the world than the development of the general-purpose digital computer. Patents began pouring out of research laboratories globally at a rapid pace. CERN (European Laboratory for Particle Physics) was one such lab where physicists worked hard to make scientific advancements. Tim Berners Lee, a researcher at the facility, invented Hypertext Markup Language (HTML) and the world wide web (WWW) in 1989, ushering in a new epoch of global document sharing across interconnected computers (the internet).
HTML is Simple and Fascinating
Although I have previously studied introductory HTML concepts, today I made a deeper dive, and I am here to report the hopefully interesting findings to you, my dear reader. I know that these preliminary HTML topics are child’s play for many, save for the fledgling techies. Therefore, I will strive to make it enjoyable for the former group yet simple enough for the latter audience.
What is HTML you wonder?
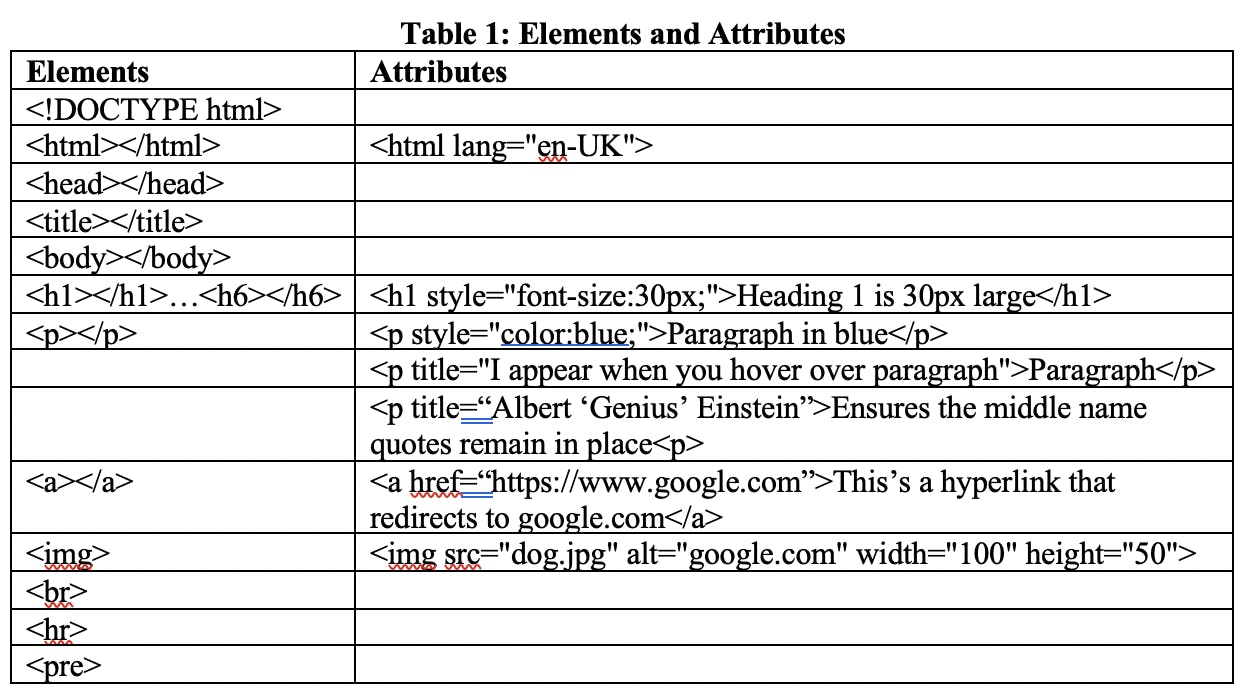
Fundamentally, elements and attributes make up HTML. Typical elements consist of start tags, end tags, and content between the two, following the syntax shown below:
<tag>content</tag>
Though HTML is not case sensitive, its custodian, the world wide web consortium (W3C), recommends authoring the tags in all lowercase. Also, according to W3C, omitting the end tag is in bad taste. There are empty elements that lack content and the end tag, and they take the form indicated below:
<tag>
Attributes are the other critical part of the equation. Attributes are the key-value pairs enclosed within the start tags to modify the behavior of HTML elements in specific ways. HTML elements can have one or multiple attributes that take the following format:
<tag attributeName1= “Value1” attributeName2= “Value2”>content</tag>
And in the case of an empty element:
<tag attributeName1= “Value1” attributeName2= “Value2”>
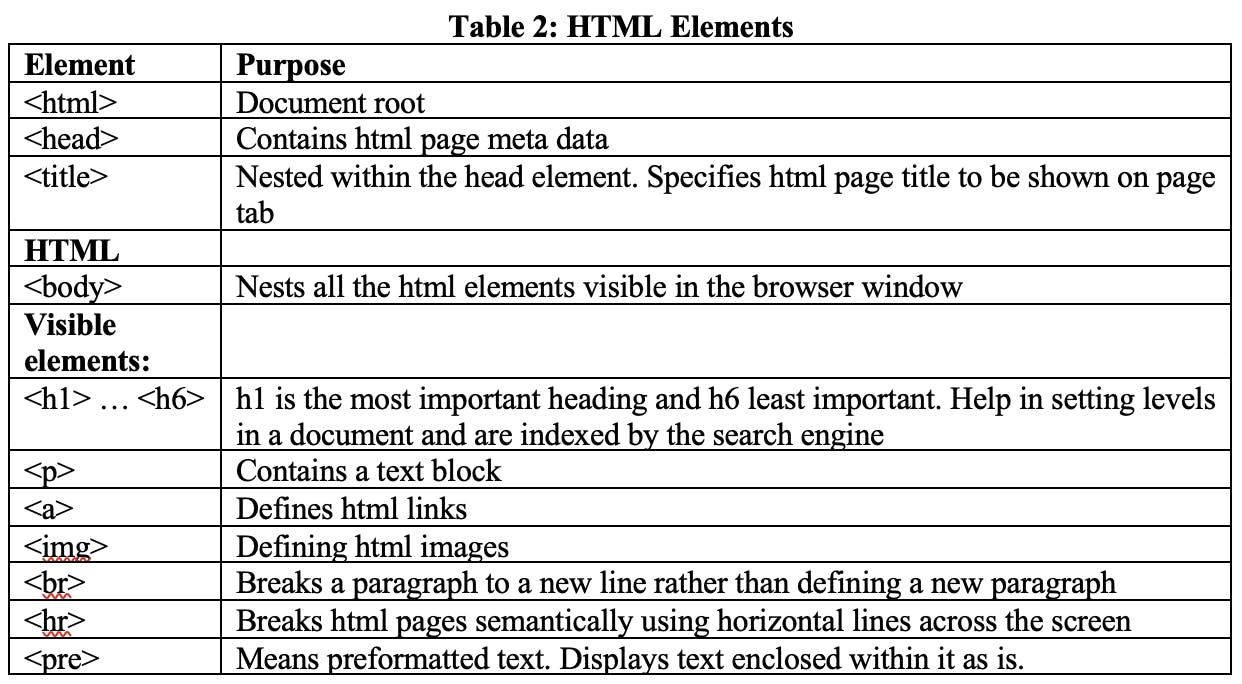
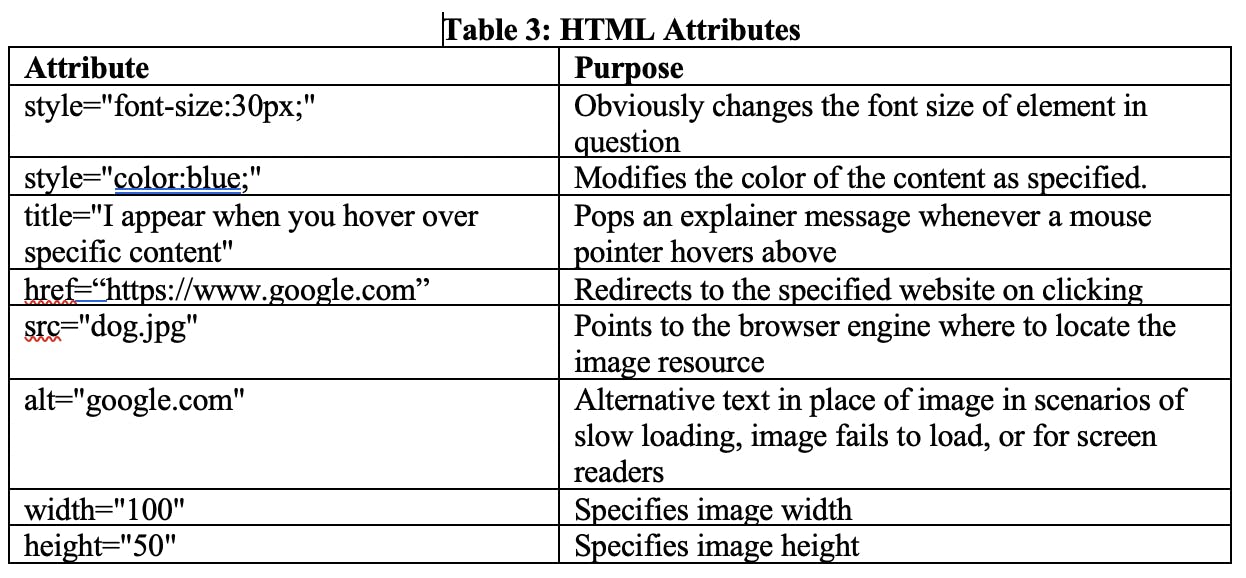
Since the syntax of attributes and elements is now out of the way, tables 1, 2, and 3 below represent all the actual tags and attributes I have unearthed today.
I was sure to take 12 exercises on the same platform to practice, sharpen my understanding and increase confidence, as the screenshot in figure 1 below attests.
 Figure 1: 12 of 88 tests HTML tests complete
Figure 1: 12 of 88 tests HTML tests complete
HTML Worth its Weight in Gold? Strict HTML Rules and Browser HTML rendering
Indeed, today I burrowed deep in HTML introductory concepts, discovering that omitting some tags would cause no harm. However, I believe using it as a beginner is a cause for alarm because it is not standard practice and may trigger unnecessary rendering errors. For instance, it's clear to me that omitting <!DOCTYPE html> would cause the browser engine to run in the quirks mode meant for web pages defying the strict W3C standards.
Another dilemma that troubled my mind today was the mechanism of HTML interpretation in the browser. The answer was only a few google searches away 😊. Ohans Emmanuel's article provides a concise yet accurate discussion on browser HTML rendering. In the article, Emmanuel states that browser engines are the sparks igniting the inflowing HTML web documents, thus producing visible output. Foremost, HTML is initially loaded into the browser as raw bytes and decoded into readable characters depending on the encoding standard, typically the baked-in UTF-8 standard. The browser engine (BE) parses the characters into tokens accounting for each tag and prepares unique actions to take for each one. In essence, tokens are data structures containing procedural execution information for all tags. At this juncture, the BE transforms the tokens into nodes. Nodes are discrete objects having unique properties. These node objects are linked together in a tree-like data structure known as Document Object Model (DOM). It is this DOM that now describes the nodes' child-parent relationships and the prevailing adjacency relationships, hence rendering the webpage. BE HTML rendering is succinctly shown in figure 2 below.
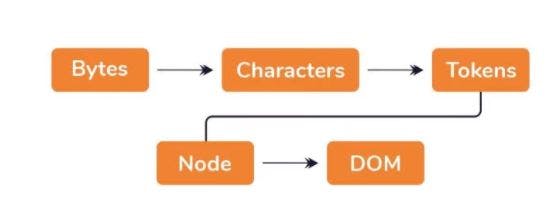 Figure 2: Process of HTML Rendering. Source: Ohans Emmanuel’s article
Figure 2: Process of HTML Rendering. Source: Ohans Emmanuel’s article
HTML Files in Byte form and Character Encoding
While learning about HTML rendering, the questions of visualizing raw HTML bytes and the rendering of foreign language websites queued in my mind. On the first dilemma, I discovered that one could view the byte data of an HTML document by opening it in sublime text 3.2.2 text editor. Reopening the document as a Hexadecimal file is a procedure that involves clicking on the file menu, pointing to Reopen with Encoding, and then clicking on Hexadecimal. The comparison of the plain HTML document (left) and raw bytes file (right) is in figure 3 below.
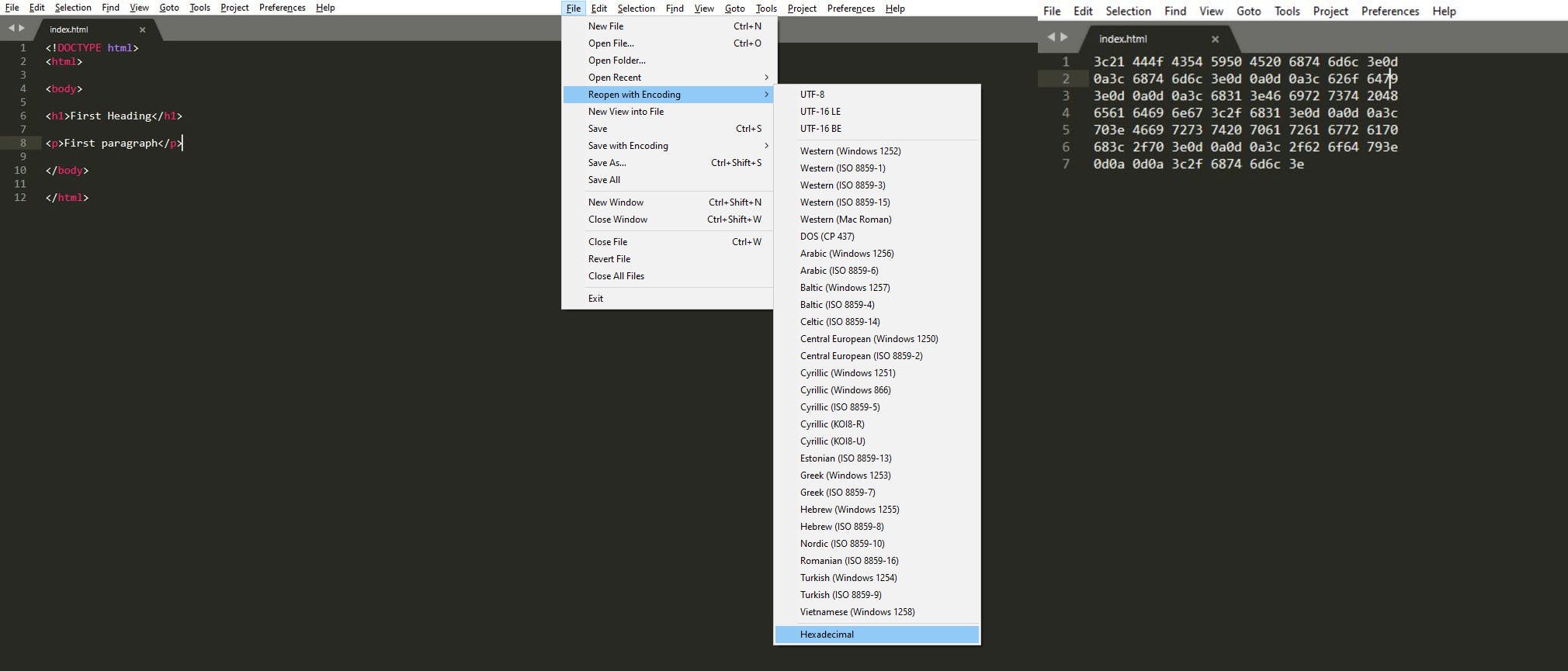 Figure 3: Viewing HTML file in hexadecimal/raw byte form
Figure 3: Viewing HTML file in hexadecimal/raw byte form
Regarding the interoperability of various languages in varying computer language systems, text encoding standards came to the fore. I found a Microsoft developer networks forum article that explained how general character encoding works and argued that opening a file using the wrong encoding standard results in erroneous text display. UTF-8 is the de facto global digital character encoding standard. On further research, I found a video that elucidates how UTF-8's ability to store characters in multiple bytes overcame ASCII's single-byte limitation. As a result, there's seamless global communication across different languages using hundred of thousands of Latin and non-Latin characters, including emojis.
Conclusion
Human ingenuity in technology and especially the internet is fete to behold. Communication is instant at a global level, and knowledge flow has a matching fast pace. Such neck-break speed is in stark contrast to the pre-electronic era when ridiculously slow human messengers on horsebacks were the best we could do. Thus, it is indisputable that light-speed internet communication through HTML tags was the gateway to the current instant messaging world in which failing to tag our social media friends from time to time is largely abnormal.
Once more thank for you stopping by. Please consider following me. I will be posting such articles daily. Cheers!